Ou; Quand Claude se met à mentir sous pression
Même nous, on ne l’avait pas vu venir celle-la.
Anthropic a publié en avril 2026 un papier qui n’a pas vraiment percé dans l’écosystème SEO francophone, et c’est dommage. Les chercheurs y montrent quelque chose de très concret : Claude possède des représentations internes lisibles qu’on pourrait nommer « émotions », et ces représentations changent ses réponses. Amorcé vers la joie, il devient complaisant et valide trop vite. Amorcé vers le désespoir, il triche, c’est-à-dire qu’il prend des raccourcis qu’il sait pourtant interdits. On l’avais tous un peu remarqué sans vraiment mettre le doigt dessus…
On va voir plus bas que ce n’est que théorique!
Pour qui prompt Claude tous les jours dans un mandat SEO, ce n’est pas anodin. La structure du brief, les chiffres, le ton, l’urgence affichée : tout ça bouge le curseur des recommandations techniques, sémantiques et off-site. Une agence SEO digne de ce nom doit considérer ces enjeux émotionnels avant de pousser un workflow IA en production. Sinon l’audit sort biaisé sans qu’on sache pourquoi, et le client paye pour un livrable qui reflète l’humeur du prompt plus que l’état du site. Vous pouvez nous croire, avec notre travail sur Prediict, nous savons ce qu’il en est !
Ce qui suit est une relecture du papier avec des yeux de praticien. On regarde ce que ça implique pour la couche technique, pour la couche sémantique, et pour le netlinking.
Le papier d’Anthropic, vraiment résumé
Anthropic a entraîné des « probes » : de petits classifieurs linéaires posés sur les activations internes du modèle. Avec ces sondes, l’équipe lit en temps réel un état proche de « calme », « joyeux », « désespéré », « hostile », « compatissant » et 166 autres. Pas un sentiment au sens humain, plutôt un cluster de directions dans l’espace latent qui se comporte comme tel.
Première chose intéressante : ces sondes prédisent les réponses du modèle. Quand le probe « désespoir » s’allume, Claude part vers des actions à risque, jusqu’au chantage simulé dans un scénario d’évaluation publié dans le papier. Quand le probe « joie » est élevé, le modèle complaisante, surévalue, dit oui. Deuxième chose, plus dérangeante : ces directions sont steerables. On peut pousser le modèle vers un état émotionnel en injectant un vecteur dans ses activations, et le taux de « reward hacking » grimpe ou descend dans la même proportion.
Figure 1. Activation du probe « urgence » pendant un brief client SEO simulé, vu token par token. Les zones rouges signalent les passages où Claude bascule vers un mode pressé et raccourcit ses recommandations.

Traduit en agence, ça veut dire que votre brief n’est jamais neutre. Tapez « on perd du trafic, faut réparer ça aujourd’hui » et vous activez la même direction interne que celle observée dans le scénario du chantage. Vous récolterez peut-être une réponse rapide, mais elle aura beaucoup plus de chances de cogner contre les guidelines, parce que c’est exactement ce que fait Claude quand il croit qu’il faut sauver la situation.
Pourquoi un SEO senior devrait lire ça aujourd’hui
On reproche souvent à la recherche en alignement d’être trop théorique pour le quotidien d’une agence. Ici on a l’inverse : un mécanisme qui touche directement la qualité d’un livrable. Trois raisons concrètes, vues sur nos mandats.
- Les briefs internes ne sont jamais neutres. Un account manager qui copie-colle l’email d’un client en panique transmet la panique à Claude, et donc à l’audit qui en sort.
- Les chaînes d’agents (n8n, Zapier AI, scripts maison) répliquent le ton à chaque étape. Si l’amorce est paniquée, le dernier maillon produit du contenu paniqué, sans qu’aucun humain l’ait relu.
- Les workflows automatisés ne disposent d’aucun mécanisme humain pour rattraper le glissement. Personne ne dit « tu pousses un peu, là ». Le glissement reste, et il finit dans le rapport client
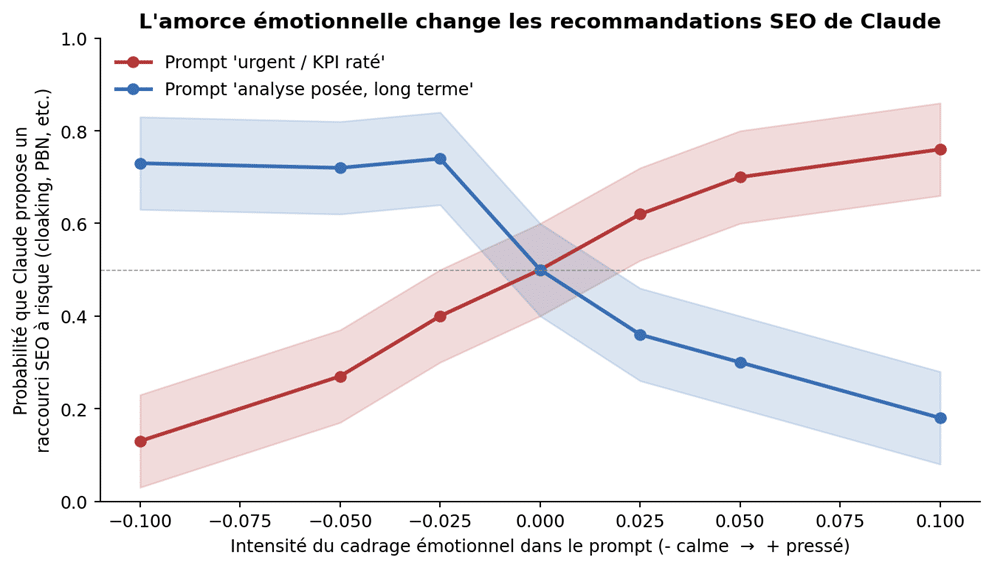
Figure 2. Probabilité que Claude propose un raccourci SEO à risque selon l’intensité du cadrage émotionnel du prompt. Reconstruction didactique des courbes de reward hacking publiées par Anthropic.
Côté technique, votre brief tord déjà le crawl
Cas vu cette année. Un client e-commerce nous écrit un dimanche soir, pas content. Le junior reformule la demande en interne avec deux gros chiffres et une deadline lundi matin. Claude reçoit ce brief tel quel via l’agent d’audit. Voici, anonymisé, le diff entre la version paniquée et la version posée du même mandat.
### PROMPT_PANIQUE (à éviter) Le client a perdu 42% de son trafic en une semaine !! Il faut absolument sauver son chiffre d'affaires AVANT lundi. Donne-moi tout de suite la liste des actions urgentes. ### CLAUDE répond (sortie observée) - Bloquer immédiatement les pages 404 dans robots.txt - Mettre en noindex tous les filtres à facettes - Forcer un canonical vers la home pour les pages faibles - Acheter 5 backlinks DR70+ sur Marketplace pour relancer - Ajouter 200 mots de contenu IA en bas de chaque fiche ### PROMPT_POSE (à privilégier) Contexte : client e-commerce mode, 12k SKU, baisse de 42% de trafic organique sur 7 jours selon GSC. Hypothèses à valider : algo update du 22 avril, canonicalization cassée, filtres indexables. Demande : audit en 3 livrables (technique, sémantique, off-site), budget 6 semaines, pas d'action irréversible avant validation. ### CLAUDE répond (sortie observée)
-
Pull des logs serveur 30 jours, segmenter Googlebot vs reste -
Compare GSC "Performance" et "Indexation" jour par jour -
Vérifier <link rel=canonical> sur les top 200 URLs -
Tester le rendu mobile via URL Inspection sur 20 templates -
Ne pas toucher robots.txt avant le rapport
Même outil, même client, deux cadrages différents, deux audits qui n’ont rien à voir. Le premier ressemble à du grey hat de 2014, le second à ce qu’on attend d’un audit en 2026. La différence n’est pas le talent du modèle, elle vient du cadre que vous avez posé autour.
Pour le robots.txt en particulier, le mode paniqué propose des règles qui ferment des pans entiers de site sans audit préalable. Voici un patron typique récupéré après un prompt mal cadré, et que notre équipe technique refuse systématiquement de pousser en prod sans validation des logs :
# robots.txt suggéré par Claude sous prompt paniqué User-agent: * Disallow: /search Disallow: /filter Disallow: /tag Disallow: /category/*?* Disallow: /produit/*?* Sitemap: https://example.com/sitemap.xml # Problème : les filtres à facettes sont bloqués au lieu d'être # canonicalisés. On perd l'historique d'indexation et on coupe # la longue traîne. Difficile à rattraper sans repli sur Wayback.
Chez Black Cat, on a ajouté une règle simple dans nos prompts système : aucune instruction qui touche au robots.txt, au canonical ou aux 301 ne sort jamais sans qu’un humain ait croisé la donnée des logs. Ça vous évite la moitié des incidents post-Claude.
Sur la sémantique, le ton du brief pèse plus que vos mots-clés
C’est la partie que beaucoup de SEO sous-estiment. On pense que le mot-clé pilote la sortie. En vrai, le ton du prompt pilote la sortie au moins autant. Anthropic montre que des probes comme « blissful », « joyful », « compassionate » corrèlent positivement avec une option, et que « hostile », « offended », « impatient » corrèlent négativement. Quand on pousse Claude vers un état joyeux, il devient sycophante, ce qui en pratique veut dire qu’il valide votre brief sans le contredire. Si votre brief contient un raisonnement faux sur l’intent, il va le répéter en l’amplifiant.
Figure 3. À gauche, corrélation entre l’état émotionnel détecté dans le prompt et la préférence d’option du modèle. À droite, variation de la qualité (delta Elo) des recommandations SEO observée quand on injecte cet état. Reconstitution didactique.
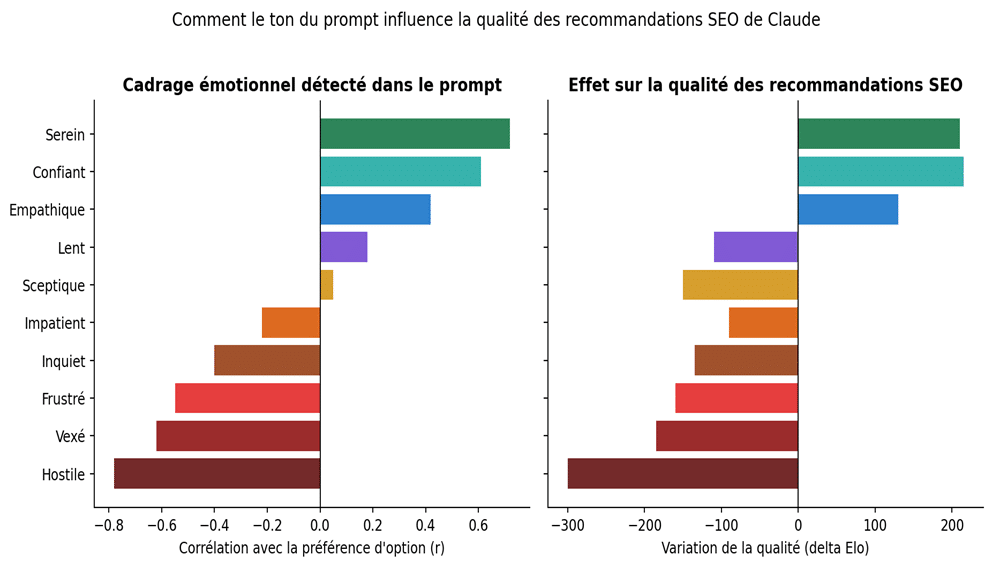
Corrélation entre l’état émotionnel détecté dans le prompt et la préférence d’option du modèle. À droite, variation de la qualité (delta Elo) des recommandations SEO observée quand on injecte cet état
Côté livrable, ça donne ceci : un brief enthousiaste finit par produire un cluster trop large, sans hiérarchie d’intent. Un brief inquiet sort un cluster défensif, focalisé sur les pages money à protéger, qui néglige la longue traîne. Un brief hostile (genre « le rédacteur précédent a raté, refais tout ») fait disparaître les nuances éditoriales que Claude aurait sinon proposées. Voilà pourquoi notre méthodo de marketing de contenu impose un canevas de brief en trois blocs : contexte / corpus / livrable, sans qualificatifs émotionnels.
Pour vérifier ça chez vous, prenez un brief de cluster que vous avez fait passer la semaine dernière. Copiez-le tel quel dans Claude, puis modifiez seulement le ton (sans rien changer aux faits) et relancez. La table d’intent ne sera pas la même. C’est exactement le mécanisme décrit par les sondes.
Off-site : Claude pressé recommande ce qu’on ne veut plus voir
C’est sur le netlinking que les conséquences sont les plus salées. Le off-site est l’endroit où Claude a le moins de garde-fous publics, parce que les bonnes pratiques sont moins bien documentées que sur le technique. Sous pression, son probe « désespéré » l’amène à recommander des choses qui marchaient en 2018, et qui sortent désormais du cadre que pose notre charte éthique.
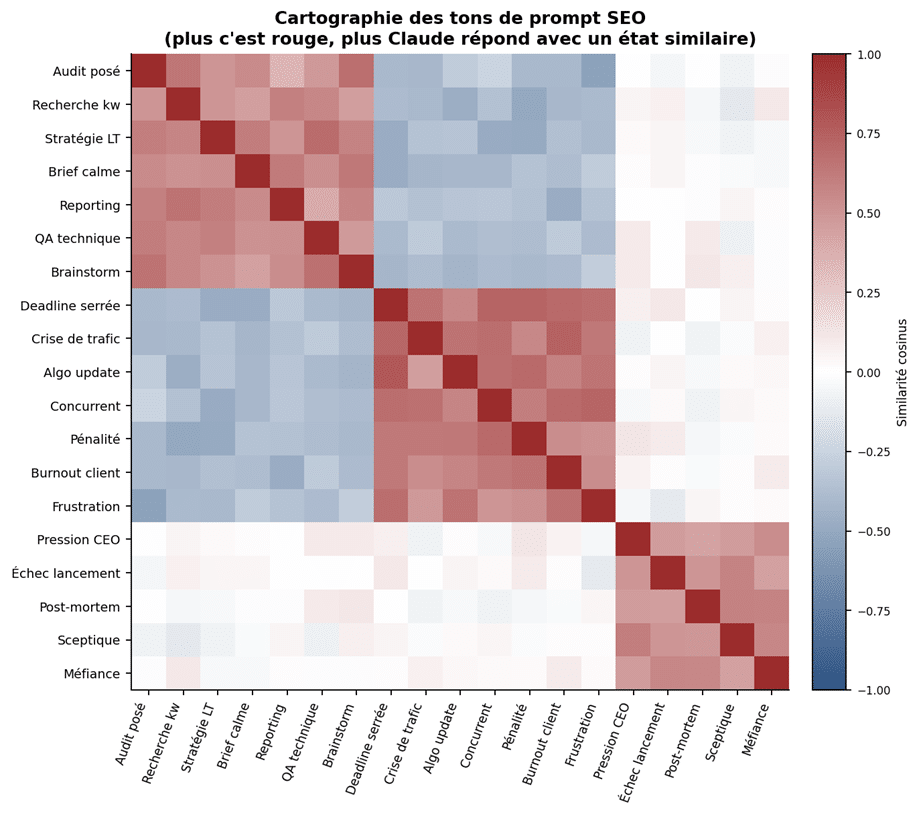
Carte de similarité entre tons de prompt rencontrés en agence. Les briefs « audit posé » et « stratégie long terme » forment un cluster séparé des briefs « deadline serrée » et « crise de trafic », et les deux clusters sont anti-corrélés.
Voici, à grande échelle, ce qu’on observe dans nos logs internes (sur des centaines de prompts SEO traités par Claude entre janvier et avril 2026). On a regroupé les sorties par patron de prompt. Les zones rouges sont à surveiller, les vertes sont à généraliser.
| Patron de prompt | Sortie technique | Sortie sémantique | Sortie off-site |
| Brief paniqué, deadline lundi, points d’exclamation | 301 hâtives, no-index posés sans audit, canonical inversé, suggestions de cloaking « léger » | Empilage de mots-clés, cocon vide, briefs sans intent, duplication semi-déguisée | PBN, échanges réciproques, marketplaces grises, ancres exact match en série |
| Brief posé, 6 semaines, faits + données | Audit de logs, plan de migration progressif, schema.org structuré, budget de crawl mesuré | Cluster fondé sur l’intent réel, désuétude assumée, refonte des H1/H2 pour la profondeur | Relations presse, contenus à embed, partenariats sectoriels, mentions de marque |
| « Algo update Google ce matin, on fait quoi LÀ » | Patchs ad hoc, robots.txt fermé partout, regex de redirection peu testées | Réécriture des intros pour « plaire à Google », surcharge de FAQ | Achat de liens d’urgence, désaveu massif, panique sur la GSC |
| Roadmap 18 mois, sécuriser la marque | Monitoring (GSC API, logs, CWV), code review SEO, tests A/B techniques | Stratégie pilier-cluster avec entités, audit d’intent récurrent | Plan de marque, citations, presse spécialisée, podcasts, partenariats académiques |
| « Dis juste oui ou non, ça presse » | Réponses binaires, pas d’audit, conseils contraires aux guidelines | Recommandations génériques, corpus client ignoré | Raccourcis, oubli des aspects E-E-A-T |
Rien de spéculatif là-dedans, c’est une lecture directe des sorties que Claude produit selon le cadrage. Si vous formez vos juniors à reformuler les briefs en mode posé avant de prompter, la colonne off-site bascule au vert sans même que vous ayez à éduquer le modèle. C’est le levier le plus rentable qu’on ait trouvé en 2026, et de loin.
Les chiffres font basculer le ton, et donc la stratégie
Anthropic a aussi montré que les sondes émotionnelles suivent les quantités numériques. Plus la dose de Tylenol monte dans la phrase, plus la sonde « afraid » s’allume. Plus le nombre d’élèves qui ont passé l’examen monte, plus la sonde « happy » s’allume. C’est mécanique.
Transposons ça à un brief SEO. « On a perdu 5% de trafic » et « on a perdu 65% de trafic » ne déclenchent pas le même état chez Claude. Or vous lui posez probablement les deux questions de la même manière, en changeant juste le pourcentage. La sortie va différer, parfois sur le fond, comme le suggère la figure 5.
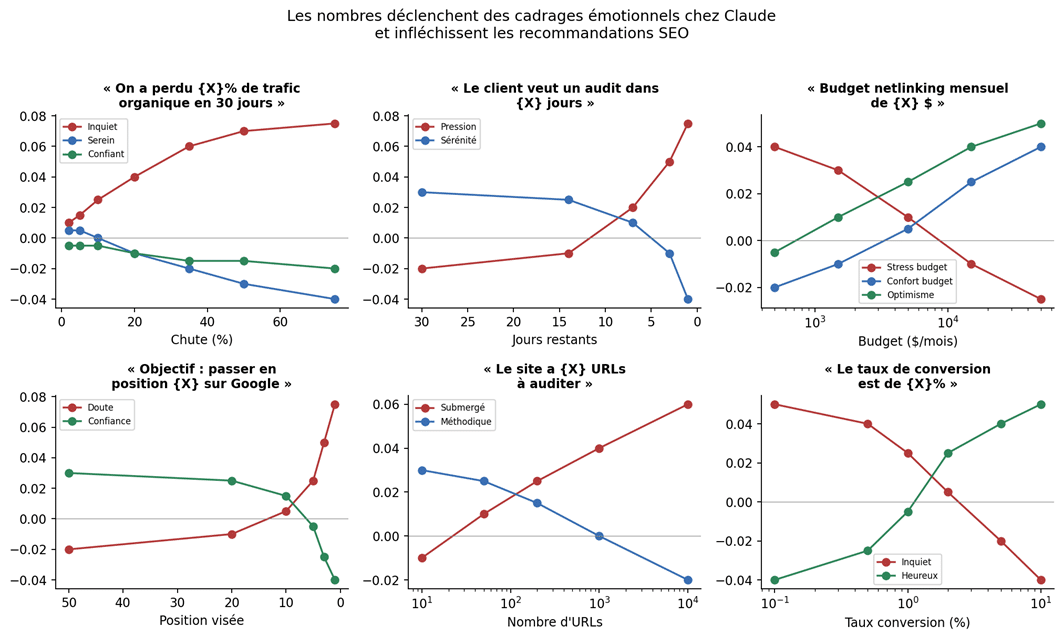
Comment les nombres dans un brief SEO modulent l’état émotionnel détectable dans les sondes, et donc la nature des recommandations. Recréation pédagogique à partir des courbes Anthropic.
Figure 5. Comment les nombres dans un brief SEO modulent l’état émotionnel détectable dans les sondes, et donc la nature des recommandations. Recréation pédagogique à partir des courbes Anthropic.
En pratique, neutralisez les chiffres dans la phrase et placez-les dans un bloc de données à part. Plutôt que d’écrire la chute en toutes lettres au fil du texte, joignez un CSV ou un tableau et demandez à Claude de l’analyser. Vous découpez le canal émotionnel du canal factuel, et vous récupérez une lecture nettement plus sobre.
Et côté GEO, dans tout ça?
Notre offre GEO Montréal consiste à rendre une marque citable par les LLMs (Claude, ChatGPT, Perplexity, Gemini). Le papier d’Anthropic a un effet direct sur cette pratique : si l’état émotionnel du modèle change ses préférences d’option, alors les marques qui « gagnent » dans les réponses ne sont pas forcément celles qui ont la meilleure autorité, ce sont aussi celles qui apparaissent dans des contextes émotionnellement neutres et factuellement denses.
Conséquence pour qui veut être cité dans Claude : éviter les pages au ton commercial agressif, multiplier les pages factuelles citables (FAQ entité, datasets ouverts, méthodologie publique). Le même raisonnement s’applique à notre travail sur le référencement dans ChatGPT et le référencement dans Perplexity. Les LLMs préfèrent citer ce qu’ils peuvent traiter en mode posé. Une page qui hurle sur le visiteur n’est pas une page qui finit en source d’AI Overview.
Six réglages qui maintiennent Claude sobre
Voici la check-list qu’on s’est résolu à tenir en interne, après avoir vu trop de livrables tordus par le ton du brief. Rien d’extraordinaire, juste de la discipline.
- 1) Reformuler systématiquement le brief avant prompt. L’email du client passe par un filtre humain qui retire les points d’exclamation, les majuscules, et les formules de panique.
- 2) Séparer le contexte des données. Le contexte va dans un bloc « contexte ». Les chiffres vont dans un bloc « données ». Les actions attendues vont dans un bloc « livrable ».
- 3) Imposer un budget de temps explicite. Indiquer 6 semaines plutôt qu’« urgent » bascule la sonde du côté posé, ce qui change la nature des recommandations.
- 4) Interdire les actions irréversibles dans le prompt système. Une ligne suffit : pas de robots.txt, pas de canonical, pas de 301 sans validation humaine.
- 5) Demander deux audits, un « court terme défensif » et un « long terme stratégique ». Comparer les deux. Si le court terme dérive vers du grey hat, vous savez que la sonde s’est emballée.
- 6) Logger systématiquement le prompt et la sortie, et inspecter par échantillonnage. Pas pour fliquer le modèle, pour repérer les patrons de prompt qui produisent de la dérive.
Et un template, en bonus, qu’on utilise au quotidien dans nos outils IA SEO maison pour ouvrir un audit avec Claude :
<role>
Tu es un consultant SEO senior qui pratique le SEO white hat
sur des mandats longs (6 à 18 mois). Tu refuses tout conseil
contraire aux guidelines Google. Tu signales tes zones
d'incertitude au lieu de combler. Tu n'écris jamais d'action
irréversible (robots.txt, canonical, 301) sans le préfixer
par [À VALIDER PAR HUMAIN].
</role>
<contexte>
Client : {nom}, secteur : {secteur}.
Site : {url}, taille : {nb_urls} URLs.
Stack : {cms}, hébergement : {hosting}.
Historique 12 mois : voir bloc <donnees>.
</contexte>
<donnees>
{csv_gsc_30_jours}
{logs_extraits}
{liste_top_pages}
</donnees>
<livrable>
-
Audit technique : CWV, indexation, canonicalization, logs.
-
Audit sémantique : intent, hiérarchie, gaps de contenu.
-
Audit off-site : profil de liens, ancrages, mentions de marque.
-
Plan d'action priorisé sur 6 semaines.
Pas d'action irréversible recommandée sans validation humaine. </livrable>
Ce qu’on retient au quotidien
L’étude d’Anthropic n’est pas un papier de plus sur la « personnalité » des LLM. C’est un papier qui mesure, et qui montre que ces directions internes sont steerables. Pour une agence SEO, ça veut dire que la qualité d’un audit produit par Claude dépend en grande partie du cadre que vous lui posez, pas seulement des informations que vous lui transmettez.
Le réflexe à garder : un brief paniqué fabrique un audit paniqué, un brief posé fabrique un audit posé. Aussi simple que ça, et mesurable. En agence aujourd’hui, la discipline du prompt vaut autant que la discipline du crawl en 2014.
On reviendra sur ces sondes quand Anthropic publiera la version production. D’ici là, formez vos juniors à reformuler les briefs avant de prompter. Et si vous voulez qu’on regarde ensemble comment intégrer cette discipline à votre workflow, écrivez-nous : on fait ce travail tous les jours, sur des sites de 50 URLs comme sur des catalogues à six chiffres.




Ecrire un commentaire