L’analyse des fichiers journaux est l’une de ces tâches que vous pourriez ne pas effectuer souvent – en raison de la disponibilité des données et des contraintes de temps – mais qui peuvent fournir des informations que vous ne pourriez pas découvrir autrement, en particulier pour les grands sites. Si vous n’avez jamais fait d’analyse de journal ou si vous ne savez pas exactement quoi chercher et par où commencer, j’ai élaboré une ligne directrice pour vous aider:
- Commencez avec quelques outils d’analyse de fichier journal
- Comprendre quels fichiers journaux sont utiles pour
- Creuser dans les données et réfléchir à une meilleure redistribution des ressources d’exploration
Les fichiers journaux sont essentiellement un journal de toutes les demandes faites à votre site pour une période de temps spécifique. Les données sont très spécifiques et plus détaillées que celles que vous pourriez collecter à partir d’une analyse, de Google Analytics et de Google Search Console combinés. En analysant ces données, vous pouvez quantifier la taille de tout problème potentiel que vous découvrez et prendre de meilleures décisions sur quoi creuser encore plus. Vous pouvez également découvrir des problèmes tels que le comportement de robots étranges que vous n’avez pas pu identifier lors d’un audit technique régulier. L’analyse des journaux est particulièrement utile pour les grands sites où une analyse nécessiterait beaucoup de temps et de ressources.
Outils d’analyse des fichiers journaux
Il existe différents outils pour cette tâche, Screaming Frog, Botify et BigQuery pour n’en citer que quelques-uns. Chez Blackcat, nous utilisons BigQuery, et screaming frog, qui est assez flexible
Quel que soit l’outil que vous choisissez d’utiliser, vous devriez pouvoir utiliser le cadre ci-dessous.
Les fichiers journaux sont une très bonne source pour:
- Découverte de problèmes potentiels: utilisez-les pour trouver des choses que vous ne pouvez pas effectuer avec une exploration, car cela n’inclut pas la mémoire historique de Google
- Identifiez les priorités: savoir à quelle fréquence Google visite les URL peut être un moyen utile de hiérarchiser les choses.
La meilleure partie des fichiers journaux est qu’ils contiennent toutes sortes d’informations que vous voudrez peut-être connaître, et plus encore. Code de réponse de la page? Ils l’ont. Type de fichier de page? Inclus. Type de robot? Devrait être là-dedans. Vous avez eu l’idée. Mais tant que vous n’aurez pas découpé vos données de manière significative, vous ne saurez pas à quoi servent toutes ces informations.
Creuser dans les données
Lorsque vous commencez à analyser les journaux, vous devez découper les informations en gros morceaux pour obtenir une bonne image globale des données, car cela permet de comprendre les priorités. Vous devez toujours comparer les résultats au nombre de sessions organiques obtenues, car cela permet de déterminer si le budget d’exploration doit être distribué différemment.
Voici les critères que j’utilise pour creuser dans le fichier journal:
- 10 URL / chemins les plus demandés
- Page status code 200 codes et non à codes 200
- URL avec paramètres vs non paramètres
- Demandes de type de fichier
- Demandes par sous-domaine
Avant que tu commences
À ce stade, vous devez également décider d’un seuil pour ce qui représente un pourcentage significatif de vos données. Par exemple, si vous découvrez qu’il y a 20000 demandes avec un code de réponse 301 et que le nombre total de demandes dans les journaux est de 2000000, sachant que les 301 ne représentent que 1% du total des demandes vous aide à regrouper cela comme un problème de faible priorité. Cela peut changer par type, par exemple, 10% des pages de catégorie avec un code d’état 404 peuvent être plus importantes que 10% des pages de produit avec un code 404.
Une fois que vous commencez à obtenir des résultats à partir de vos données, vous devez déterminer si le comportement du robot d’exploration actuel est la meilleure utilisation des ressources d’exploration. La réponse à cette question vous indiquera quelles devraient être les actions suivantes.
Les 10 URL / chemins les plus demandés par rapport aux sessions organiques qu’ils conduisent
Grâce à l’analyse des fichiers journaux, vous découvrirez souvent quelques chemins ou URL spécifiques qui ont reçu un nombre de demandes considérablement plus élevé que les autres. Il s’agit généralement d’URL liées à partir de la plupart des modèles, par exemple à partir de la navigation principale ou du pied de page, ou à partir de sources externes, mais ne génèrent pas souvent un nombre élevé de sessions organiques.
Selon le type d’URL dont il s’agit, vous devrez peut-être ou non prendre des mesures. Par exemple, si 40% des ressources sont utilisées pour demander une URL spécifique, est-ce la meilleure utilisation des ressources d’exploration ou pourraient-elles être mieux réparties?
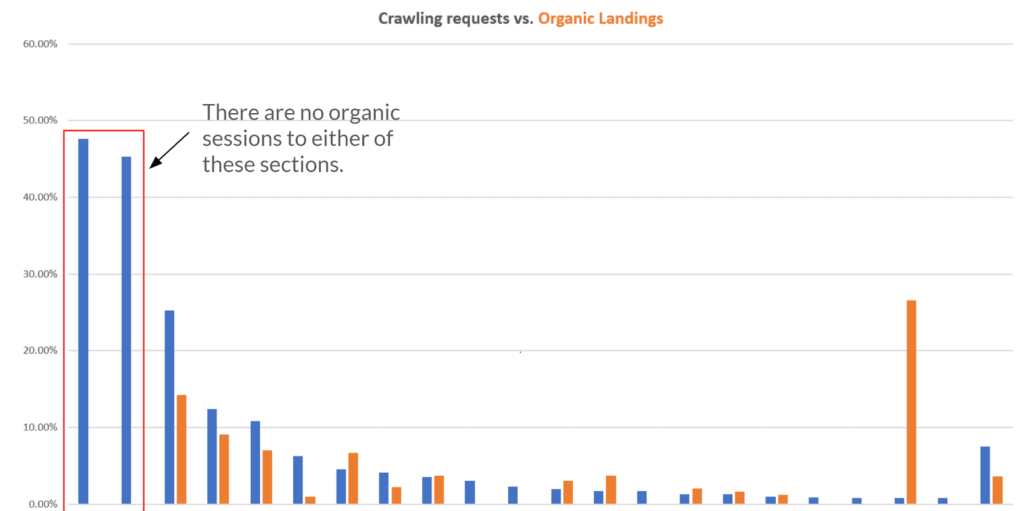
Voici un exemple de la répartition des principaux chemins demandés à partir de l’analyse des journaux et de leur comparaison avec les sessions organiques qu’ils conduisent:
Cette comparaison sur un graphique vous permet d’identifier facilement comment les ressources d’exploration pourraient être mieux réparties. Les deux premières barres bleues montrent que la majorité des demandes concernent deux chemins spécifiques qui ne conduisent à aucune session organique. Il s’agit d’un moyen rapide d’identifier immédiatement les gains importants: dans l’exemple ci-dessus, l’étape suivante serait de comprendre quelles sont ces URL et où elles se trouvent pour ensuite décider si elles doivent être explorées et indexées ou quelle action supplémentaire peut être requise. . Un audit technique ne vous donnerait pas les informations que je montre dans le graphique.
Code de réponse de la page
Selon qu’un pourcentage élevé des demandes de journal est une page de codes non 200, vous souhaiterez peut-être approfondir cette zone. Ici, vous devez interroger vos données pour découvrir quelle est la ventilation de la page de codes non-200 et en fonction des résultats, creusez plus loin, en priorisant ceux qui ont le pourcentage le plus élevé.
Voici un exemple de panne de pages de codes non 200:

Comme visible ci-dessus, près de 50% de toutes les demandes sont adressées à une page de codes de statut autre que 200. Dans ce cas, examinez plus en détail chaque code d’état pour découvrir de quel type de pages ils proviennent et quel pourcentage chacun représente. En remarque, si vous rencontrez également un grand nombre de pages avec un code d’état 304, il s’agit d’une réponse du serveur essentiellement équivalente à un code d’état 200. La réponse 304 indique que la page n’a pas changé depuis la transmission précédente.
Voici quelques vérifications courantes que vous devez effectuer sur les pages de codes autres que 200:
- Existe-t-il des modèles de liens internes pointant vers ces pages? Une exploration du site pourrait y répondre.
- Y a-t-il un nombre élevé de liens / domaines externes pointant vers ces pages?
- Le code d’état de ces pages est-il provoqué par certaines actions / situations? (c’est-à-dire que sur les sites de commerce électronique, les produits abandonnés peuvent devenir 404 pages ou
- 301 redirections vers les catégories principales)
- Le nombre de pages avec un code d’état spécifique change-t-il au fil du temps?
URL avec paramètres vs non-paramètres
Les URL avec des paramètres peuvent provoquer une duplication de page, en fait très souvent ce ne sont qu’une copie de la page sans paramètres, créant un grand nombre d’URL qui n’ajoutent aucune valeur au site. Dans un monde idéal, toutes les URL découvertes par les robots d’exploration n’incluent pas de paramètres. Cependant, ce n’est généralement pas le cas et une bonne quantité de ressources d’exploration sont utilisées pour analyser les URL paramétrées. Vous devez toujours vérifier le pourcentage du total des URL paramétrées des demandes.
Une fois que vous connaissez la taille du problème, voici quelques éléments à considérer:
- Quel est le code de réponse de la page de ces URL?
- Comment les URL paramétrées sont-elles découvertes par les robots?
- Existe-t-il des liens internes vers des URL paramétrées?
- Quelles touches de paramètres sont les plus trouvées et à quoi servent-elles?
Selon ce que vous découvrez au cours de cette phase, des actions liées aux étapes précédentes peuvent s’appliquer ici.
Demandes de type de fichier
Je vérifie toujours la répartition des types de fichiers pour découvrir rapidement si les demandes de ressources telles que des images ou des fichiers JavaScript constituent une grande partie. Cela ne devrait pas être le cas et dans un scénario idéal, le pourcentage le plus élevé de demandes devrait concerner des pages de type HTML, car ce sont les pages que Google comprend non seulement, mais aussi les pages que vous souhaitez bien classer. Si vous découvrez que les robots d’exploration dépensent des ressources considérables pour des fichiers non HTML, c’est un domaine à approfondir.
Voici quelques éléments importants à étudier:
- D’où les ressources sont-elles découvertes / liées?
- Doivent-ils être explorés ou doivent-ils simplement être utilisés pour charger le contenu?
Comme d’habitude, vous devez garder à l’esprit la question la plus importante: est-ce la meilleure utilisation des ressources d’exploration? Sinon, envisagez d’empêcher les robots d’exploration d’accéder à ces ressources dans un but d’indexation. Cela peut être facilement fait en les bloquant sur robots.txt, cependant, avant de le faire, vous devriez toujours vérifier avec votre développeur.
Demandes par sous-domaine
Vous n’aurez peut-être pas besoin de cette étape si vous n’avez pas de sous-domaines, mais sinon, c’est une vérification que vous devriez faire pour découvrir un comportement inhabituel. En particulier, si vous analysez les journaux d’un domaine spécifique, les demandes vers d’autres domaines doivent être quelque peu limitées, selon l’organisation de votre lien interne. Cela dépend également si Google considère les sous-domaines comme votre site plutôt que comme un sous-domaine distinct.
Comme pour les étapes précédentes, il s’agit de la première ventilation de vos données et, sur la base des résultats, elle devrait vous dire si quelque chose mérite d’être approfondi ou non.
Quelques éléments à garder à l’esprit dans cette section:
- Le robot doit-il passer moins / plus de temps sur les sous-domaines?
- Où les pages de sous-domaine sont-elles découvertes sur votre site?
Cela pourrait être une autre occasion de redistribuer le budget d’exploration aux pages que vous souhaitez que les robots d’exploration découvrent.
Pour conclure
Comme pour de nombreuses tâches de référencement, il existe de nombreuses façons de procéder à une analyse de journal. La directive que j’ai partagée vise à vous fournir une méthode organisée qui vous aide à réfléchir à l’exploration des ressources budgétaires et à la meilleure façon de les utiliser. Si vous avez des conseils sur la façon dont vous pensez de l’exploration des ressources budgétaires, veuillez laisser vos conseils dans un commentaire ci-dessous.




Ecrire un commentaire